During a recent series on MOOCs and testing, the only subject I didn’t get to was peer-grading, the mechanism some massive classes are using to allow students to submit assignments that cannot be machine scored (such as written papers or other “artifacts” whose grading still requires the subtlety of the human mind).
We’ll put aside attempts to computerize the grading of essays for another time, and instead focus on the primary tools used to add written assignments and similar human-graded projects to a MOOC course.
Keep in mind that this piece is informed by my experience with a grand total of one course that includes peer-grading. But it’s also informed by experience in the testing industry that exposed me to the core technique MOOCs are using to scale subjective assignments: assessment rubrics.
While the term “rubric” can be used generically to describe any set of instructions for evaluation, in the professional testing world a rubric is a formal set of criteria that assigns a specific number of points to different aspects of a graded project.
Rubrics I’ve created or reviewed in the past used 0-3, 0-4 and 0-10 scales (with each point level being associated with a specific set of features the grader should be looking at when assigning scores). And most rubrics ask graders to assign these point levels to multiple components of an assignment. For example, the rubric below was used to score a student’s written answer to a question involving copyright, trademark and other intellectual property issues:
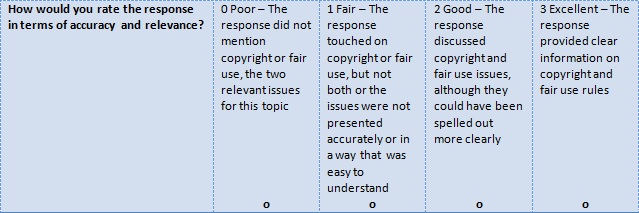
You’ll notice that each numerical score includes a detailed description of what type of answer qualities for this grade.
Essay scoring has long used rubrics to make grading more efficient and cost-effective. In fact, the efficiency of rubric-based scoring (coupled with tools that automate the entire review and grading process) are why it’s been possible to add essays to the SAT and ACT without doubling or tripling their price.
My Coursera Modernism and Post Modernism class leverages the time-tested technique of rubric scoring to support a class where the grade is based entirely on how well students do on eight assigned papers. And to get around the need for the teacher or his staff to grade tens of thousands of assignments, the job of grading has been handed to students themselves with each student who submits a paper being asked to pass judgment on the work of three others.
The rubric we have used for every assignment is the same and consists of three criteria (Quality of Argument, Quality of Evidence and Quality of Exposition), each of which can be assigned one of four following scores. For instance, Quality of Argument are graded based on this scale:

Graders are also given the opportunity to leave comments on why they graded each of these criteria as they did, as well as provide feedback on the essay as a whole.
Having received grades on several assignments (as well as grading many more), I don’t think I’ve gotten (or given) a grade that could be described as grossly unfair, which means that the system is working reasonably well. This conclusion is supported by reports I’ve heard about that found high correlations between peer-review grades and how instructors would grade the same essays themselves.
While that’s all well and good, the professional testing geek in me has a few points that need to be included in any discussion of the quality and effectiveness of this technique, a set of critiques I will provide in detail tomorrow.
[…] http://degreeoffreedom.org/moocs-and-peer-grading-1/ […]